ML Systems Design Interview Guide

One of the trickiest interview rounds for ML practitioners is ML systems design. If you’re applying to be a Data Scientist, ML Engineer or ML Manager at a big tech company, you’ll probably face an ML Systems design question. I recently tackled this question at a few big tech companies on my way to becoming a Staff ML Engineer at Pinterest. In this article I’m going to talk about how to approach ML Systems Design interviews, core concepts to know and I’ll provide links to some of the resources I used.
This is Part 2 of my ML Engineering Interview Guide, make sure you check out Part 1, my generic Systems Design Interview Guide that’s applicable to both ML and distributed systems design interviews.
Table of Contents
ML Signals
This interview question is designed to get signals on how good you are at applying ML/AI to real world applications.
What are companies looking for:
- Theoretical knowledge of ML
- Do you know the right terms to describe ML concepts
- Familiarity with methods
- Familiarity with industry and state of the art solutions
- Hands on practical knowledge that comes from real world experience
- An understanding of how an ML application would be implemented in terms of computer infrastructure
- Technical leadership: communication skills, ability to organize concepts
- Product leadership: do you design ML solutions to provide for the needs of users and product designers
ML Systems Questions
I spoke to a lot of companies during my interview process including Pinterest, Spotify and Facebook. To be sure, this isn’t comprehensive so my experiences won’t apply everywhere! I’m not going to break my NDAs and say any of the exact questions I was asked, but I’ll give an overview. Compared to standard software engineering loops, there’s more variation between how each company evaluates candidates on ML skills. This really came through in the ML systems design questions. Some companies blended the questions with regular distributed systems designs while others focussed more on theoretical ML.
However, based on my experience and research, it’s very common for consumer big tech companies to ask questions about recommender systems in their system design. This makes sense:
- Recommender systems play a key role in modern consumer applications
- It’s a constantly evolving field with many creative approaches
- It can utilize a wide range of ML techniques
- There’s also a non-trivial computer infrastructure component
Note that this is common for interview loops for ML generalists like myself. If you’re a researcher in NLP, image recognition or some other specialized field, you may get interview design questions focussed on that. Eg. If you’re coming from the Siri voice recognition team and interviewing at Alexis, you can probably expect some deeper ML questions on voice recognition.
What are some example questions?
A well known example question is to design Facebook’s content feed recommendation system. In fact it’s so well known, that it may have been retired from the question base :) We’re not just limited to content feeds though:
- Recommend artists to follow on Spotify
- Recommend restaurants to in Google maps
- Recommend add on items for a cart in Amazon
You get the idea: given some background and current info about the user, recommend something from a big dataset.
Design Process
As I mentioned in my first article, I think of systems design questions as improv presentations. The interviewer gives you a task, you clarify it and then present a solution. It’s crucial to go into the interview with a game plan for discussing your design. There’s a lot of ground to cover in creating an ML system and you also need to show some real depth in a few areas. Here’s a flow for an ML question, in reality, it’s easy to blend these topics at any time or take a deep dive. Make sure you look for clues from the interviewer that they want to hear more about a topic, or if you’ve covered enough and you can move on. Don’t forget that you’re not only trying to please the interviewer, but the panel of people who will be reviewing your performance later. Don’t give up any opportunities to show your experience and skills. Remember, unlike other interview rounds, you’re driving this interview, and you want to show both technical knowledge and leadership skills.
Product Objectives and Requirements Clarification
Once you hear the question, do not dive right into a solution! The first thing you should do is clarify the business/product priorities for the system. For most consumer applications, there’s two high level business objects: engagement and revenue. You want to be a participant in working through how to translate these goals into system objectives. So if the interviewer says they want to increase user engagement, you can start a discussion breaking that down: new user retention, increasing session length, number of sessions, etc. Most products have a North star user action that’s used as a proxy for engagement or satisfaction, like the number of interactions with Instagram posts per day. You don’t need to get into specific KPIs yet (save that discussion for online evaluation.) At this stage, the goal is to spend a little bit of time gathering information and showing off some of your product sense. You might not need all of the information you get, but it will help you think about the problem and give you a bit of time to consider different angles.
Next, you can discuss product requirements.
- Is this feed being calculated in real time or can you use batch?
- Does this apply to all user segments? How many users are there?
- How quickly do items get stale? (eg. do we need to content that’s only a few seconds old?)
You also want to bring up technical scaling requirements (don’t make assumptions, it’s key to clarify this out loud):
- How many items are you dealing with?
- How many users are there?
- What are the peak number of requests per second? Or day?
- Hammer out timing SLAs (eg. we’ll incorporate user actions into recommendations within X seconds/minutes/hours)
These will limit the approaches you can use and affect your infrastructure.
Often, the interview question may be about the real product the company develops (as opposed to some theoretical situation.) That means you’re expected to make some common sense assumptions. Does Facebook need to support multiple languages? There’s no need to explicitly ask that, but you should call out any assumptions you’re making. You can also clarify any preconceived notions you have about the solution. For example, you might call out that it seems important to be able to show recent posts from friends, but you could get clarity on what ‘recent’ means, posts from the last 5 minutes or the last 24 hours. What’s the oldest content you would recommend?
High Level Design
Once you’ve gathered some initial requirements and have a deeper understanding of the problem, you can discuss a high level approach. It’s best if you can generate a list of high level solutions and call out pros and cons. Iterating through multiple approaches doesn’t lend itself to every problem though, sometimes there’s one well known high level approach. I think it’s best to stick with well known industry patterns, there’s room for creativity in the application details. This is also where it helps to be aware of common ML/AI solutions in industry.
Look for buy in from the interviewer along the way. Incorporate feedback on areas to focus on and see if they bring up red flags or criteria you’ve missed. This is also a spot to make sure you’ve fully understood the problem setup, before you get too deep in a solution.
One of the most important design decisions is whether the system is real time, pre calculated batch or some hybrid. Real time systems limit the complexity of the methods available while batch calculations have issues dealing with staleness and new users.
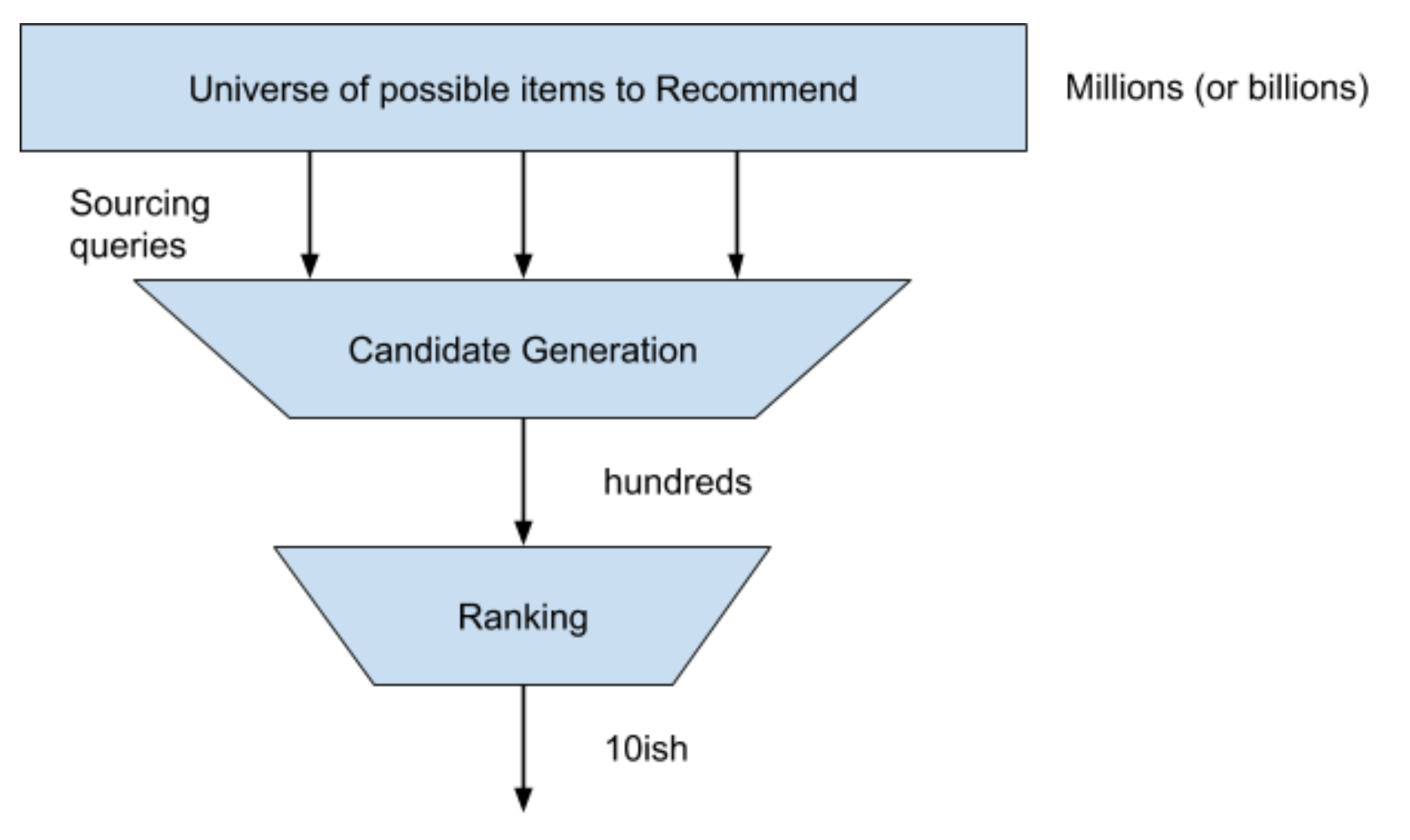
For problems like real time personalized user feeds, there’s a very common two stage architecture:
- A candidate generation stage to quickly produce a medium sized list of items to consider
- A detailed ranking model to select the top X items to return, using a slower higher performance model
Data Brainstorming and Feature Engineering
Two of the crucial signals you need to provide at this interview are the ability to think of useful data to feed into your models and your knowledge about transforming raw signals into usable numeric features for your models. Here’s a hint, this is probably something you can think about ahead of time for your interview. For the company you’re interviewing at, think about the useful data sources and features you could use. At the same time, many models have thousands of inputs, so you can’t spend the whole interview cycling through this. You can split this up into a couple layers of abstraction.
Data Sources
These are the high level sources of signals. Eg. if you’re personalizing the results of a Youtube video search, there’s a few data sources for features:
- The user doing the search
- Each video that can be recommended
- Interactions between the user and each video
- The search query
It’s worth it to be pretty exhaustive in naming all the high level data sources you can think of, there shouldn’t be that many (less than a dozen.)
High Level Features
Within each data source, you can iterate on the types features available. It’s good to call out some example specific features, but it would take too long to be exhaustive about these. Eg. for a Facebook user you have features like:
- Demographics: Age, gender, nationality, language
- Session: time in session, number of items viewed
- Post History: items liked, items disliked, posts created
- Friends and following: How many friends do they have, posts liked by friends, celebrities/interests followed
Obviously there’s many more items here. Notice that the concepts are still vague, and would require clarification to actually use in a model. Eg. don’t just leave a feature as ‘history of items liked’, that’s not a numeric value you can train a model with.
Feature Representation
Now you want to discuss actual numeric representations of features. There’s so many potential features here that you should just pick a subset that provides coverage of a wide range of feature engineering techniques. These are some common techniques to create final numeric features:
- Numeric values: demeaning, scaling (eg. dividing by the max or standard deviation), removing outliers (eg. values greater than the 99th percentile). There’s also binning, quantization etc.
- Categorical values: If a categorical value has a dozen or fewer values, you can use one hot encoding. Eg. the OS the user’s client is using. If you need to represent a variable with lots of possible states, it gets unwieldy to use one-hot encoding so you can switch to an embedding.
- Text: There’s a lot of valuable data in text. It’s good to have some basic understanding of NLP concepts so you can discuss how to present text to a model. It’s become common place to use embeddings for this, so understand how systems like BERT and Word2Vec can be used. You don’t need to be an expert, but a bit of knowledge of common techniques will make this so much smoother.
- Complex: How can you represent complex items like a user’s history of viewed posts as a numeric vector? Similar to text embeddings, you can build up a feature by representing each post as its own embedding, then combining the embeddings (through aggregation or concatenation.) For modern AI systems, it should be clear that embeddings play a huge role, so you should understand the math and concepts behind this.
Make sure you talk about why you’re applying transformations and call out possible options. Discuss assumptions you’re making about the data, eg. it’s skewed or falls within a certain range. Why is it even important to squeeze a numeric value between 0 and 1? Is your choice of model sensitive to how the features are prepared?
Feature Selection
It’s not always a good idea to throw the kitchen sink at your model. Discuss some techniques for feature importance ranking and selection. Bear in mind this is fairly high level and abstract since you don’t have the data in front of you. You can also discuss regularization when you start to talk about models.
Candidate Sources
If you’re discussing a recommendation system, the first stage is looking at a large set of items to recommend and narrowing this down. If the universe of possible items to recommend is very large, then it’s not feasible to evaluate each one in real time. You need a heuristic to generate an initial list of candidates. What are some common heuristics?
- Items that are ‘close’ to the user in an embedded space
- Items that are similar to items the user has interacted with
- Items that are globally popular across a large population
- Items that friends of friends like
- Items that match some type of search criteria
There’s a lot of room for creativity here and you might be able to think of some options that are very application specific. Note that you can use more than one source!
Infrastructure
Some companies may not care at all about infrastructure for this interview, while others may actually combine ML with Distributed Systems. Make sure you’re clear on expectations for how much you should discuss the actual infrastructure for the interview. Even if infrastructure isn’t important, you should still keep in mind the limitations that modern computing imposes. No, you won’t be able to run a million high dimensional pictures through a Resnet model in real time. See the Infrastructure Components section below for some important ML infrastructure.
Model Development
Modelling is one of the key skills for any ML practitioner, and you want to show your depth in this area. There’s so many techniques for modelling, it’s good to cover some breadth instead of naming one solution.
Model Types
Here’s where you discuss the actual modelling techniques you can use for your various components. As with the rest of the design, we’re moving from higher levels of abstraction to more specific. We’ve already described the data inputs to our components, now we want to break down higher level components into lower level ML model types:
- Binary classifiers
- Multi-classifiers
- Regressions
For our recommender example, the ranking component can be built with an ML model. We can rank the candidates by their predicted outcome for the user. For example, maybe based on our initial discussions, perhaps we’re trying to increase engagement by showing posts that increase user interactions with the posts. There’s lots of ways to do this:
- A binary classifier that predicts whether the user will interact with the given post
- A multi classifier with predictions for commenting, liking or hiding a post
- A regression that predicts the number of interactions a user will make with the post
The actual model is still a blackbox, we’re not yet discussing how to train the model.
Offline Training and Evaluation
Models are trained and evaluated offline. First, you should discuss the data you’ll use for training. This is a gotcha that might catch people without much real world experience by surprise and often requires a bit of thought. For example, if we’re training a binary classifier to predict whether a user will ‘like’ a post, there’s a lot more posts in the world that the user didn’t like than liked! Should we only train the model using posts that the user observed in their feed which they didn’t like? What if they ended up liking a post later on, do we only label data based on their first impression? How do we deal with data imbalances which are very common in recommender systems? These are issues that all real world recommendation systems deal with, you can read about some of the solutions in industry papers!
You should also discuss how you’d organize the data for evaluation, eg. k-fold, holdout etc. You should discuss the metrics you’d use to compare models. For classifiers you should discuss what’s more important, precision or recall, especially considering their effect on users. How does it affect the user experience to have a ‘false positive’ versus missing the ‘right’ answer?
Modelling Techniques
Now we have the inputs and expected outputs specified for our models. We can discuss actual implementation. I think it’s good to go over a few options and discuss their pros and cons. Eg. Suppose we want a binary classifier to predict whether a user will interact with a given post. Here’s a few quick modeling techniques you can raise:
- Logistic regression: Fast to train, very compact, but only finds linear relationships between features.
- Gradient boosted trees: Better performance than logistic regressions, can find non-linear interactions, typically doesn’t require much tuning.
- Deep Neural Networks: produces state of the art solutions, deals with non-linearities, requires lots of tuning and can require a lot of computing resources to train.
Don’t forget to bring up advanced issues specific to these models. Eg. For logistic regression you could talk about regularization with lasso or adding interaction features to deal with non-linearity. If your model training uses an optimizer, talk about the loss functions you can use. Talk about hyper-parameters and design choices for each model. This is a chance to show off your depth and go beyond the typical shallow ideas people can grok from a data science tutorial!
Online Evaluation
We’ve trained our model with the hyperparameters that led to the best evaluation metrics in our holdout data. Should we just launch this to the entire user base? Unless you’re fresh out of school, you should know the answer is NO!
Make sure you bring up how you would launch the system and actually evaluate whether it’s achieving its business objectives. This is almost always via A/B testing, which has lots of its own nuances. Talk about which metrics you’d measure and statistical tests you’d perform for an A/B test. You can go into some depth talking about ramping patterns and issues that arise with A/B testing.
Model Lifecycle Management
Once the model is launched, what other ops work will there be? How can we monitor the model to make sure it’s healthy and what operations will we have to do to keep the model performing well. What happens if we want to update our features?
Leveling
Systems design questions (for both software and ML) go a long way towards determining your level, are you junior, senior or staff. Here’s a few detailed areas that show industry experience:
- Business/Product considerations (eg. cannibalizing revenue or engagement)
- Model lifecycle management (detecting feature drift, performance drop)
- Updating data (eg. embeddings)
- How to split up work between workers or teams
- Measuring effects on business
- Offline and online evaluation
- Data issues and remediation, eg. skewed data, seasonality
ML Concepts
This article can’t go into detail on every ML concept you should know, but I’ll list a bunch that I think are important. Note that these aren’t just useful for the design interview, but they could come up in other ML interviews as well.
Quick Cheat Sheet
- Offline objectives
- Distances (cosine, dot, hamming, jaccard, levenshtein)
- Precision, recall, F1, calibration
- RMSE, Ranking, maps, SSE
- Ranking: NDCG, p@k, r@k,
- Online evaluation
- A/B testing
- Business KPIs: revenue, retention, engagement
- Feature Engineering
- Continuous: demean, normalize
- Discrete: one-hot, embeddings
- Embeddings
- PCA
- Training
- Test, train, holdout
- K-folds cross validation
- Training sample selection (eg. negative sampling)
- Models
- Linear regressions
- Boosted Trees
- Deep learning
- Deep Learning
- Understand theoretical background: optimizers, gradient descent, back prop
- Recommendation Systems
- Collaborative Filtering
- Candidate Selection
- Ranking metrics
Infrastructure Components
You likely won’t have to provide a detailed infrastructure plan like in a distributed systems interview, but you should be able to talk about the infrastructure you could use to implement your solution. These help meet the scale and timing SLAs you would have discussed in the requirements gathering.
- Realtime approximate nearest neighbours systems (eg. Annoy, Faiss.)
- Text indexing systems (Lucene, Elasticsearch)
- Database and distributed data systems like Spark
- Serving systems (TFX)
- Model tracking and Management systems (Kubeflow, MLFlow)
Embeddings
Embeddings are a key building block in powering modern AI applications. You can’t treat them like a black box. Make sure you understand what they represent and techniques for learning them. Can you embed a user and item in the same space? How can you combine embeddings? Do you need to ‘retrain’ your embeddings if a new item is added to the catalog? Do you need deep learning to learn embeddings?
Nearest Neighbours
For recommendation systems, nearest neighbours can be very useful, especially if you’ve embedded your candidates into a lower dimensional space where distance represents similarity. For candidate generation, you often want to select the k closest items in a catalog. How can you do that without evaluating every single item? You should understand LSH and have general knowledge about the existence of open source solutions like Spotify’s Annoy and Facebook’s Faiss. This Google Cloud article is helpful.
Deep Learning
This is another key technology that plays a large part in many state of the art solutions. It’s important to have a good understanding of key concepts but there is so much ground to cover here. Here’s what I think the key topics to understand are:
- Theoretical Fundamentals: Nobody will ask you to derive back-propagation using vector calculus. However, you should know the major concepts and how they fit together. Do you know the difference between gradient descent, back propagation and optimizers like Adam? What is convolution? How does a convolution layer ‘pick’ its filters?
- Building blocks: What are the low level layers and design choices you can make? What are some common activation functions and when are they used? What loss function will you use for your problem? It’s good to take a look at the Keras API to see if there’s any layers or activation functions that are new to you.
- Real World Techniques: DNNs are finicky, and companies are willing to pay for people who have spent some time in the trenches. What’s your process for hyper parameter selection? What are some key hyper parameters and design choices? What are things to look out for while training a DNN? How can you use transfer learning to cut down on development time? Can you describe regularization techniques like batch norm or l1/l2 penalties?
- Architectures: You might not have hands-on experience with cutting edge architectures, but it’s good to be familiar with what’s out there and have a high level understanding of how it’s used. Examples are wide and deep networks, transformers, inception modules. Focus on how they could fit into a solution, not necessarily all the math and details that power them. What problem did they solve? How do they work at a high level? What application were they used on?
For the most part, I found that I wasn’t grilled too ‘deeply’ (pun) on deep learning. There are lots of ML positions that don’t touch deep learning. This is a pretty wide list of the topics that may come up during an interview. Nobody knows everything though, it’s perfectly fine to miss a few random topics.
Pre Interview CheckList
Suppose you just heard from the recruiter that you passed your phone screen. Congratulations! Your reward is a full day of interviews, including systems design. How can you prepare ahead of time?
- Be familiar with core ML concepts and infra listed above (hopefully you’ve already been preparing for this)
- Go over questions for requirements gathering. It’s easy to forget key questions when you’re nervous!
- Prepare the flow for how you’ll discuss your design. I’d do a practice run.
- Brainstorm user features, item features and sources of data signals at the company you’ll be interviewing at. It’s possible you’ll get asked something completely unrelated, but you’ll be thankful if these do come up.
- Make sure you understand the main entities for the company’s product. Eg. If you’re interviewing at Pinterest you’d want to look at what’s in the homefeed, understand what a Pin is, see how users can interact with a Pinboard etc. This makes it easier to understand concepts and requirements. Showing familiarity with the product is also a great way to make the interviewer picture you as ‘part of the team’ instead of an outsider.
Recommendation Resources
Here are some resources I found useful for studying up on recommendation systems.
Concepts and Background
- Google Developer Intro to Large Scale Recommendation Systems
- Dive Into Deep Learning Recommendation Chapter
- Coursera Lecture on Recommendation System Evaluation Metrics
- Wide and Deep Networks
- Collaborative Filtering
Reference End to End Architectures
- Alibaba Cloud’s Recommendation System Architecture Article
- Azure’s Reference Architecture for Recommendations
- Google Cloud’s Reference Article for Building a Real Time Rec Sys with Embeddings
Industry Papers
These papers show there’s a wide range of ways to create state of the art recommenders, it’s definitely not a cookie cutter problem. Pay attention to the setups, how they do offline and online evaluation.
- Deep Neural Networks for Youtube Recommendations (2016) - How Youtube uses embeddings for candidate generation
- Recommending what video to watch next: a multitask ranking system (2019) - Youtube’s multitask learner for ranking
- Instagram Explorer recommendation system - they made their own language for non-tech people to quickly develop and test candidate sources
- Pinterest Pixie - How Pinterest treats pin recommendations as a graph problem where edges represent pins being on the same board
- Real-time Personalization using Embeddings for Search Ranking at Airbnb
- Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
- Deep Reinforcement Learning for Online Advertising in Recommender Systems (TikTok) - this uses Reinforcement Learning for recommendations